Exporting selected model data for external analysis
Data scientists can export snapshots of the adaptive models that drive Pega Customer Decision Hub™ predictions from the Adaptive Decision Manager (ADM) data mart for further analysis in their favorite analytical tool. To limit the scope of the export to the data of interest, learn how to build data flows to populate a data set that contains all relevant data.
Transcript
Data scientists continuously monitor the state of their adaptive models. For an in-depth analysis of the adaptive model data, they can export the data to use in analytical tools like Python or R. This demo shows you how to build a data flow in Dev Studio to populate a data set with the model data that is relevant to you. The GitHub repository CDH Tools is publicly available, and the tooling helps to easily build meaningful plots and more.
U+ Bank uses Pega Customer Decision Hub™ to determine which credit card offer to show on their website when a customer logs in.
For each offer the customer is eligible for, an adaptive model based on the Web Click Through Rate model configuration determines the likelihood that the customer will click on the web banner.
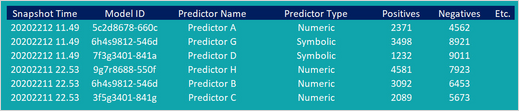
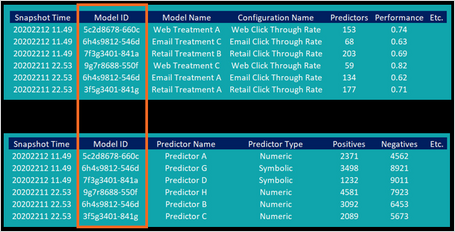
As a data scientist, you may want to export the data for these specific models from the ADM data mart for further analysis. Two database tables contain the required information and populate two data sets in regular updates or at the request of the user. The Model Snapshots data set contains snapshots that include the model ID, the model name, the configuration name, and model attributes such as the number of predictors, the model performance, and many others.

The ADM Predictor Snapshots data set contains snapshots of the binning of individual predictors.
You can export the raw data sets that contain all available data on adaptive models in the system, but to limit the size of the exports you may want to select the data that you are interested in before exporting. To select the model and predictor snapshots of models based on the Web Click Through Rate model configuration, create data flows to populate a data set that contains only the relevant information.
Data flows are scalable and resilient data pipelines that you can use to ingest, process, and move data to one or more destinations. A data flow consists of components that transform the data in the pipeline and starts with a source component.

To start building a data flow that selects the snapshots of the models that you are interested in, use the Model Snapshots data set as the source.
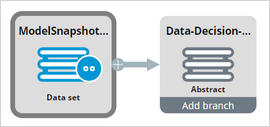
Next, add a filter component that only lets the snapshots of the models through that are based on the Web Click Through Rate model configuration.

In a second data flow, use the ADM Predictor Snapshots data set as the source.
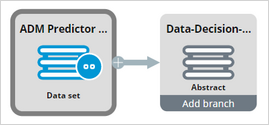
You can use the abstract output of the first data flow, containing the Web Click Through Rate model data, to select the relevant predictor snapshots from the ADM Predictor Snapshots data set, based on matching model IDs.
To do so, you add a Compose component and you configure the SelectedModels data flow as the second source. Compose the ADM Predictor Snapshots with the output of the SelectedModels data flow into a property that holds the model data. The condition is that the Model IDs match up.

Add a filter component to filter out any predictor snapshots that do not match up to one of the selected models.

As the destination of the data for the selected models, use a Decision Data Store data set. The underlying storage for this type of data set is an Apache Cassandra database, which can be exported in the JSON format.
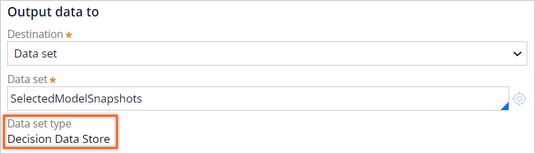
To export the data set containing all available model data for the models based on the Web Click Through Rate model configuration for external analysis, you run the data flow that you have just created. After you run the data flow, you can export the output dataset in a JSON file format.
Alternatively, you can also store the results of the data flow in a File data set that is configured to be in the repository of your choice. For each predictor snapshot, the data set contains all predictor data, and also the data from the matching adaptive model snapshot.
This demo has concluded. What did it show you?
- How to build a data flow to export a subset of the ADM data mart.
- How to create a Decision Data Store data set based on a Cassandra table.
- How to export ADM data for analysis in external tools by running a data flow.
This Topic is available in the following Module:
If you are having problems with your training, please review the Pega Academy Support FAQs.
¿Quiere ayudarnos a mejorar este contenido?