Case design patterns
Design patterns overview
Design patterns are definitions of reusable components or solution patterns applied to solve common recurring issues. As part of a COE team, a PCLSA should use case design patterns specific to their business domain, which helps the team quickly build solutions that are both reusable and maintainable.
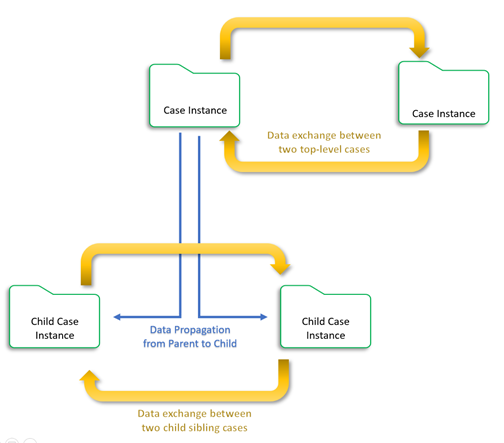
Pega’s notion of cases is unique. In general, they model a business process. Pega cases consist of one or more stages with steps and may contain child cases that form a case hierarchy. A parent case may interact with a child case and vice versa. Cases can, but rarely, interact with sibling or peer cases without being part of a case hierarchy. For example, it is not necessary to create a child case to update an existing parent case. Top-level cases may update each other.
The following design patterns can categorize case interactions.
- Divide and Conquer (most common)
- Enrollment/Add a Task to a TODO list
- Data Instance First
- Limited Availability and concurrency
- Sibling cases, one updating the other
Divide and Conquer
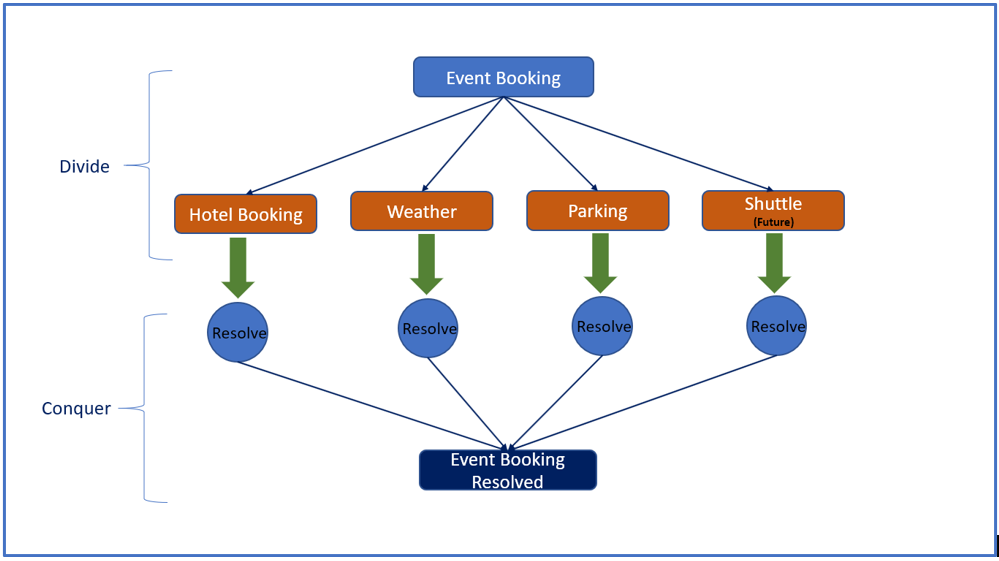
Divide and Conquer is a well-known computational problem-solving algorithm. The work to be performed is broken down into smaller, independently solvable units, which, in turn, can be broken down into even smaller units. When each child unit of work completes, it notifies their parent unit of work. When the final child unit of work of a parent is notified, that parent then notifies its parent, and so on. Eventually, the parent that does not have any parent, meaning the top-level case, observes that every child unit of work has been completed. When that occurs, the algorithm halts.
The major benefit of the Divide and Conquer approach is that sibling units of work can be solved in parallel. This significantly reduces the overall time to complete the work compared to sequential processing. This approach also provides a more significant opportunity for reuse.
In the business processing realm, a major benefit of the Divide and Conquer approach is that different units of work can be routed to the appropriate people, groups, or work queues that have the right skills to accomplish the work efficiently. Goals and deadlines can be established for getting the work completed. It is a simple matter to visualize the degree to which work has or has not been completed relative to a complicated case such as a claim.
A sample representation of the Divide and Conquer design pattern within the Booking application context is shown in the following image.
Enrollment/Add a Task to a TODO list
The Enrollment/TODO list design pattern is implemented in Pega through UI pages. The design allows an Object-Action approach. An object might already exist that is selectable or has already been selected for viewing. The user then tells that object what to do. Example actions include update or delete.
Within the context of an existing object, it is also possible to tell the computer to perform the Create action against a new object. The expectation is that the new object is associated with the existing object. The new object does not need to be a child case or any case for that matter. The new object might instead be a data instance that references the existing object.
A major benefit of this design pattern is that locking issues are avoided. For example, a data instance can be created that references an existing case instead of making a child case of the current case. Data is inserted; nothing is updated.
A second benefit is that if a single service-level agreement (SLA) applies to all of the entered data items, it is faster and more convenient for the entered data to be treated as a “TODO list” than filling that person’s worklist with multiple child case assignments. Divide and Conquer is not applicable as there is only one “worker.” The only benefit derived from using child cases is that work can be tracked at a finer-grained level if each data item has an SLA.
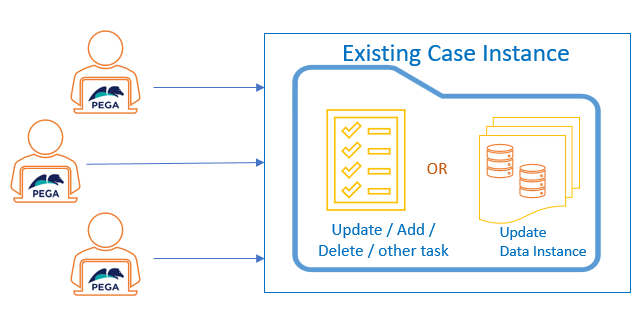
Data Instance First
The Data Instance First design pattern demonstrates how data related to a case is persisted before creating a case.
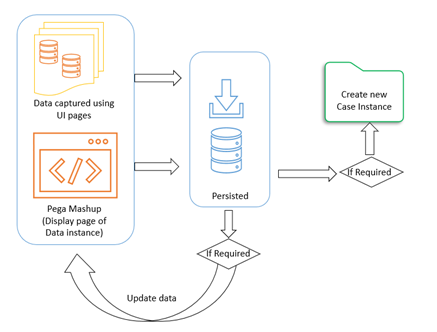
For example, when using mashup, it is not necessary to create a case immediately. Instead, the case's data can be persisted before the case is created. In this example, a mashup interface is configured as Display a page instead of Create a new case.
Note that the mashup's Create a new case option can also be related to the Data Instance First design pattern. Create a new case is directly supported by the Case Designer in Pega Platform™ version 8.5 with the addition of the Create stage. The difference between Display a page and Create a new case is that with Display a page the decision of whether a case should be created is made on the server after a Data instance is persisted.
With the Create a new case option, the decision has already been made to create a case, although temporary. The pyIsMashup circumstance template makes it possible to disguise the fact that a case has been created but not yet persisted. In particular, the pyCaseMainInner section can be circumstanced to display only the Mobile Main Case Panel section template. The rest of the Case Worker portal features, such as the Navigation menu, Recents, Related Content, and Participants, are not displayed.
A simple flat data class that has no embedded pages can be quickly persisted to the CustomerData schema. This, however, would be a significant constraint from a UI data entry perspective. Ideally, the UI would also support the entry of data instances associated with the original data class. A solution would be to define a View data class where a field group list has been added to the Model data class's definition. Because the CustomerData schema does not allow embedded pages, each page within the View data class's field group list needs to reference the Model data instance.
A case can be created after the data from the View data class has been persisted. A Pega API "cases" POST case can be invoked to create the case. For example, an Org-Data-MemberView Data class contains an Org-Data-Member field group. After an instance of Org-Data-Member is persisted, a D_CreateMember data page calls a “cases” Pega API REST Connector. The POST request content page contains a MemberGUID property, the value being the pyGUID of the persisted Org-Data-Member instance. The case that is created has a MemberGUID property, where the POST request's content page sets the value. The case can also possess an Org-Data-Member data reference property defined as a data page Lookup. The MemberGUID property supplies the parameter to that Lookup data page.
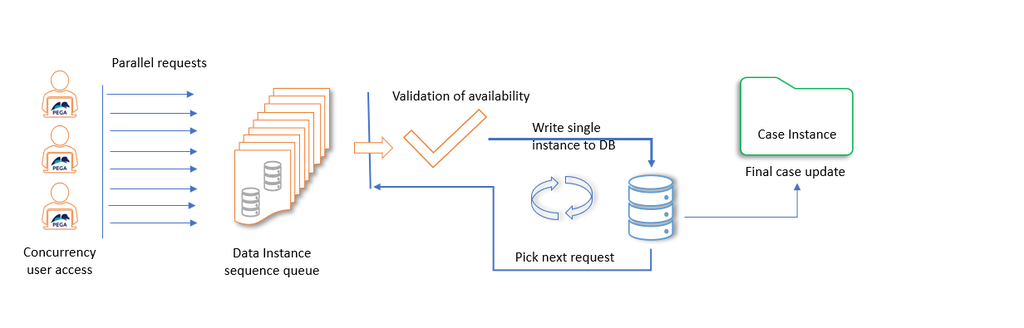
Limited Availability and Concurrency
This design pattern resembles the Enrollment/TODO List pattern in that:
- Something pre-exists, such as a case.
- Later, several things, such as data or cases, want to be associated with the pre-existing item.
A specific example that demonstrates this would be a ferry line that transports vehicles. A Trip case represents the ferry. Persons apply to reserve space on a particular Trip for themselves as well as their vehicle.
The Limited Availability + Concurrency design pattern differs in that:
- There is limited capacity. For example, there is a limit to the number of passengers and vehicles allowed on the ferry.
- Concurrency management is critical.
Regarding concurrency management, suppose two reservations are made at the same time for the same trip. There is only enough remaining capacity to honor one of the reservations; the other attempt needs to be added to the end of a waiting list. Are Reservation child cases the best solution to this problem?
The answer depends on the locking configuration. If a locking configuration is such that the parent and all child cases are locked simultaneously, this configuration solves the problem of the overbooking problem because only one reservation can be made at a time. However, no one else can enter their reservation data in parallel, which is also a potential waste of resources.
If locking configuration is such that the child case does not lock the parent case, this introduces a potential overbooking problem. To add a child case to a parent case, the parent case must be opened and locked. If the trip capacity is near its limit and multiple reservations are being placed simultaneously for that trip, additional validations must be performed to ensure the capacity is not exceeded.
For example, if the ferry's capacity is 500, it does not make sense to create that many child cases. A simpler and faster approach is to insert or update Reservation data instances without attempting to lock anything. Reservation data instances reference the Trip case. The time it takes to write a single row to a single database table is short compared to the time needed to execute a lock-query-save-commit-unlock process.
Sibling Cases, one updating the other
The Sibling Cases update design pattern is represented by sibling cases interacting with one another at the same level in the case hierarchy. This might be two top-level cases or two child cases with the same parent case. For example, suppose case A is related to case B. If there is a period of time where case B's status is dependent on the status of case A, there is no reason for case B to be a child case of case A. Both cases can be siblings to accomplish this behavior.
For example, in the Ferry scenario, a Trip case life cycle ends when the ferry reaches its destination and passengers have disembarked. A Reservation case, implemented as a sibling case and not a child case, can continue forward to stages such as Billing, Refund, or a Satisfaction Survey. If the Reservation case is implemented as a child to the Trip case, it can continue forward if the parent case is Resolved. However, the process defeats the initial reason for implementing it as a child case.
The decision to implement interacting cases as a sibling relationship requires making a decision on how best to implement that relationship. Possibilities include (but are not limited to) using the Update a case flow shape or using the Queue-For-Processing method in an activity.
This Topic is available in the following Module:
If you are having problems with your training, please review the Pega Academy Support FAQs.
Want to help us improve this content?