レポートとデータウェアハウス
概要
組織では、ウェブアプリケーション、レガシーアプリケーション、およびその他のソースのデータを組み合わせて、リアルタイムまたはそれに近い状態で意思決定を行う場合が多くあります。 多くの組織では、ビジネスインテリジェンスソフトウェアを使用して、データの収集、フォーマット、および保存を行い、これらの意思決定を行うためにこのデータを分析するソフトウェアを提供しています。
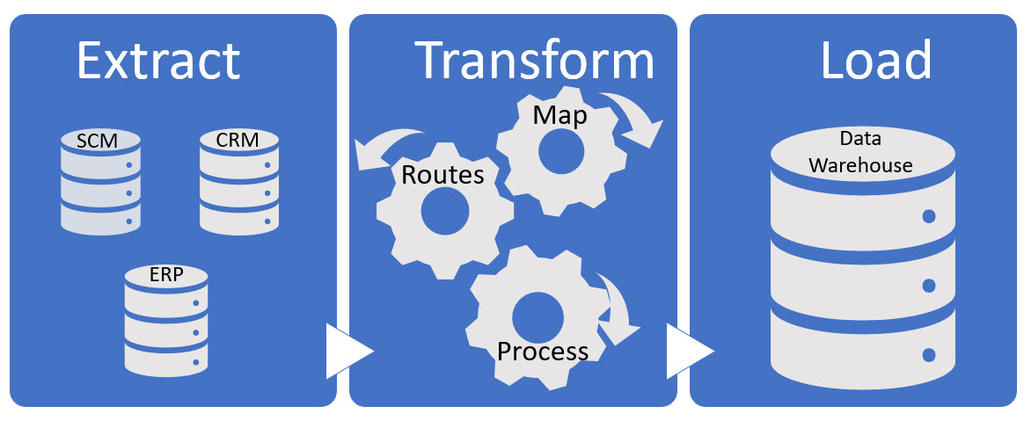
データウェアハウスは、レポート作成やデータ分析に使用されるシステムです。 データウェアハウスは、1つ以上の独立したデータソースから統合されたデータの一元化リポジトリです。 抽出、変換、および読み込み(ETL)プロセスでは、データウェアハウスで使用するデータを準備します。 次の概念図は、レコードのシステムからデータを抽出してウェアハウスに格納し、そのデータをレポートツールで使用できるようにする、一般的なエンドツーエンドのプロセスを示しています。
重要なのは、Pegaアプリケーションでのレポートの設計、または外部レポートツールの活用のどちらに決定するかで、アプリケーションのパフォーマンスに影響を与えることです。 たとえば、レポート要件として、指定された時点でワークバスケットにあるアサインメントの数を表示する必要がある場合、アサインメントワークバスケットテーブルでレポートを作成することが適切です。 複数年分のケース情報を分析して傾向分析を行う場合は、代わりにその目的に合ったレポートツールを使用します。 Pegaアプリケーションのエンドユーザーポータルからそれらのレポートへのリンクを提供できます。
Business Intelligence Exchange
Business Intelligence Exchange(BIX)は、本番アプリケーションからデータを抽出し、データウェアハウスへの読み込みに適した形にフォーマットできます。 BIXは、ルールセットと、コマンドラインで実行されるスタンドアロンのJavaプログラムで構成されるオプションのアドオン製品です。 BIXプロセスで抽出されたBIXデータは、XMLまたはカンマ区切り(CSV)でのフォーマットや、データベースへの直接出力が可能です。 次の図は、Pegaデータベースからデータを抽出し、下流のレポートプロセスで使用するためにデータを準備する様子を示しています。
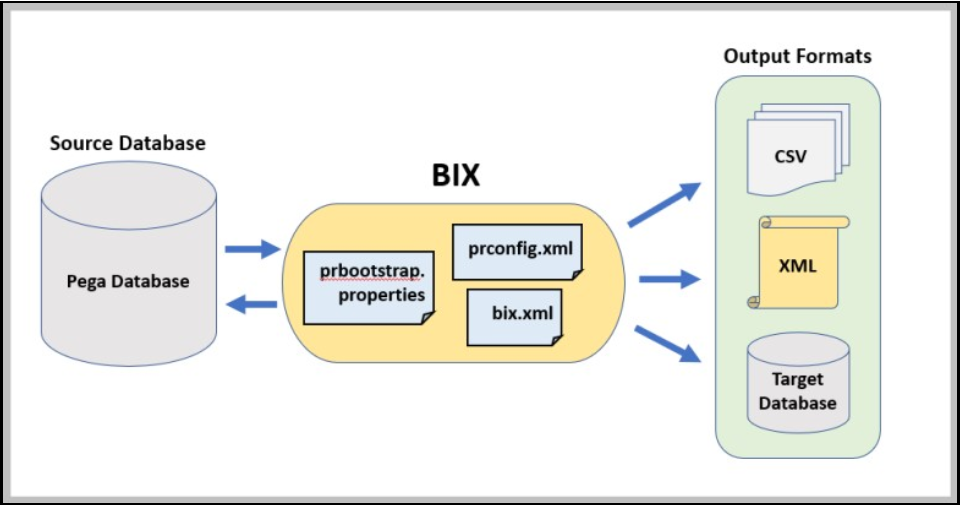
BIXの詳細については、ヘルプトピック「Business Intelligence Exchange」を参照してください。
Elasticsearch
レポート生成のパフォーマンスを向上させるには、データベースに対して直接SQLクエリーを使用する代わりに、Elasticsearchインデックスに対してレポートディフィニッションを実行できます。 デフォルトでは、Elasticsearchインデックスに対するレポートディフィニッションの実行は無効であり、Elasticsearchでサポートされていない機能を持つレポートには適用されません。 Elasticsearchインデックスに対してレポートクエリーを実行できない場合、Pega Platform™では自動的にSQLクエリーを使用します。
Elasticsearchは、最終的には一貫性のあるストレージです。 レポートディフィニッションをElasticsearchインデックスに対して実行できるようにすることで、強い一貫性が必要ないことを示します。

データ取得の環境設定は、pyContent.pyGetCachedDistinctValueの値を設定することでダイナミックに設定でき、仮想レポートをサポートするUIコンポーネントで使用したり、レポートを実行するアクティビティにこのパラメーターを渡したりすることができます。
フィルターで文字列比較演算子を使用するレポートで、データベースへのクエリー実行の代わりにElasticsearchに対してクエリーを実行できるようになりました。 Elasticsearchクエリーでは、以下の演算子がサポートされます。
- 次の値で開始、次の値で終わる、次の値で始まらない、次の値で終わらない
- 次の値を含む、次の値を含まない
- 次の値より大きい、次の値より小さい、より大きいか等しい、より小さいか等しい
Elasticsearchに対してクエリーを実行できない場合、クエリーはデータベースに対して実行されます(クエリーに結合が含まれている場合など)。 Elasticsearchに対してクエリーが実行されたかどうかを判断するには、Tracerツールを使用してQuery完了イベントタイプを有効にします。
レポートソースとしてElasticsearchが選択される可能性を高めるには、カスタム検索プロパティルールフォームの「Use dedicated index」を選択します。
このトピックは、下記のモジュールにも含まれています。
- レポート戦略の定義 v3
If you are having problems with your training, please review the Pega Academy Support FAQs.